




TL;DR
AI can measure spoken English with real accuracy, but how well it works depends on the test design, accent diversity, and what is actually being scored. Modern AI English proficiency tests look at fluency, grammar, pronunciation, and vocabulary, then map those results to the globally recognized CEFR scale. The technology is solid. The bigger question is whether it is being used thoughtfully.
Recruiters hiring across borders have been quietly adopting AI English proficiency testing for a while now. It is not exactly new. What is still worth examining, though, is whether those scores hold up when it actually matters, meaning when a hiring decision is on the line, and the candidate is sitting in Lagos or Bangalore or São Paulo. Do the numbers reflect real ability? Mostly yes.
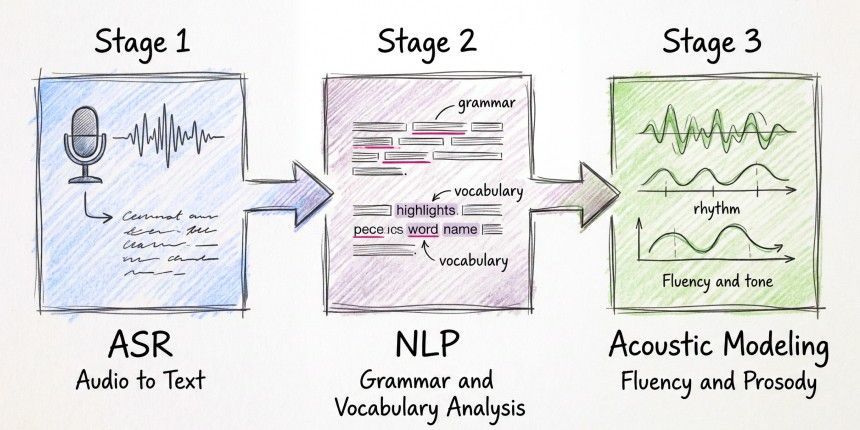
How AI Actually Evaluates Spoken English
It starts with automatic speech recognition, or ASR, which converts spoken audio into text. Not just the words either, it picks up pauses, timing, and phonetic detail that a basic transcript would flatten. From there, natural language processing reads through that text and checks grammar, vocabulary, and whether the ideas connect logically. A third component, acoustic modeling, listens for rhythm and stress in the voice. That last piece matters because fluency is not just about word choice. It shows up in how someone moves through a sentence.
Here is what separates a transcription tool from something useful for hiring: a transcription tells you what was said. A proper assessment tells you how well, and gives that a score a recruiter can do something with.
One design choice worth knowing about is the use of structured prompts. The candidate hears a question, gets a fixed window to respond, and the system captures that response. It keeps things consistent. Free conversation is richer, but it is harder to score fairly across hundreds of candidates, which is why most commercial tools lean toward guided tasks.
What the Benchmarks Show and What They Don't
The standard measure for ASR accuracy is word error rate, or WER. Lower is better. In 2016, Microsoft reported a WER of around 5.9% on the Switchboard conversational speech benchmark, which matched human transcription accuracy on the same recordings. Since then, the leading systems have pushed below 5% on clean audio.
That is genuinely impressive. But WER is a narrow number. It only captures how accurately the system heard what was said. It tells you nothing about whether that person could walk a frustrated customer through a billing issue or present a proposal to a senior team. Those skills are what workplace English proficiency actually means, and transcription accuracy alone cannot measure them.
The more relevant benchmark for hiring is how closely AI scores line up with human raters. ETS, which built the SpeechRater engine used in TOEFL scoring, has published research showing correlations between automated and human scores in the 0.7 to 0.8 range. Two human raters scoring the same response tend to agree at a similar level. AI is not outperforming humans here, but it is in the same ballpark.
Real-World Deployments: What Case Studies Reveal
Some of the clearest evidence comes from tools that have been running in the real world for long enough to accumulate meaningful data.
Pearson's Versant English Test has been used by enterprises and government agencies for over two decades, scoring candidates on sentence repetition, reading aloud, and open responses. Their published validity studies show strong alignment with human CEFR ratings, particularly in the B1 to C1 range, where most professional hiring decisions sit.
ETS's SpeechRater has been compared against human raters across hundreds of thousands of spoken responses. The finding is consistent across their studies: AI scores fluency, pronunciation, and grammar well. Extended responses that require logical structure and coherence are harder. And that gap actually matters. Grammatical accuracy and the ability to communicate a complex idea clearly are not the same thing. AI is better at catching the former.
In customer service and BPO hiring, automated spoken English screening is already standard. The main advantage organizations report is consistency. A human interviewer scoring thirty candidates in a day will not apply the same standard to candidate one and candidate thirty. An AI English proficiency test does not drift.
Where AI Language Testing Has Real Limits
Background noise is the obvious one. A candidate recording from a loud apartment gets a noisier signal, and that can drag scores down for reasons that have nothing to do with English ability. Solvable with audio quality checks built into the test. But it takes deliberate design to get there.
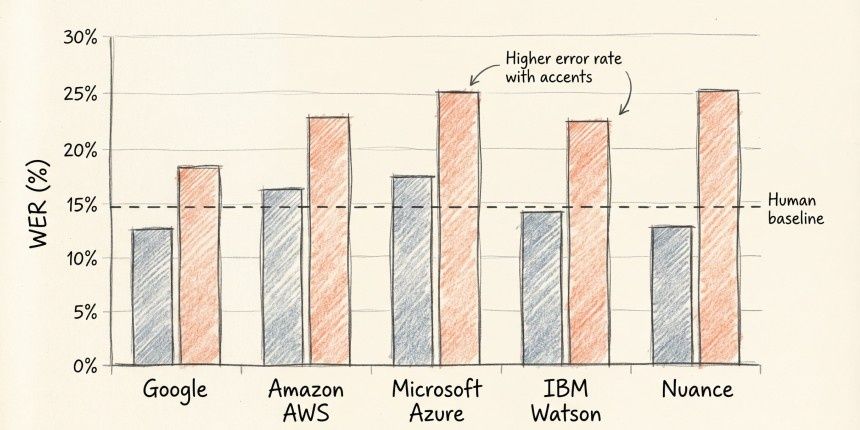
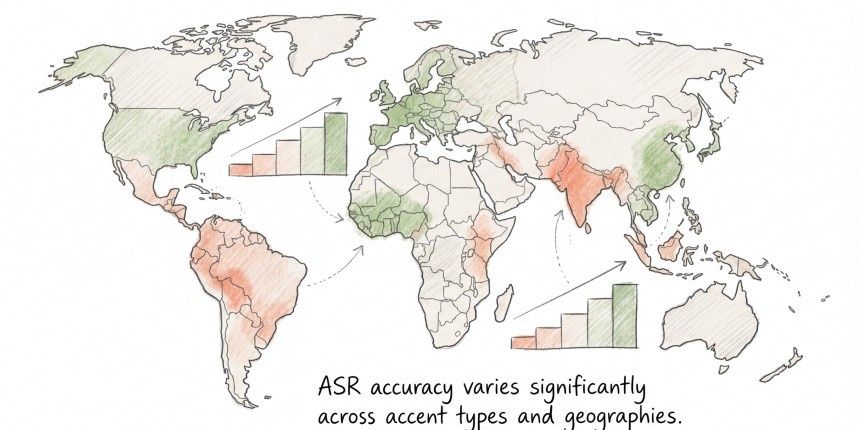
Accent handling is the harder problem. A 2020 PNAS study by Koenecke et al. tested five major commercial ASR systems and found that error rates for African American Vernacular English speakers were more than double those for white speakers. The cause is not mysterious: a model trained mostly on one type of speech will not perform equally on others. For hiring tools, that is a serious concern. A candidate with a South Indian, Nigerian, or Brazilian accent might score lower on pronunciation, not because they are hard to understand, but because the model was not built with their phonetic patterns in mind.
Then there is the question of whether the test actually measures what it says it does. AI scoring grammar from a transcript can flag something as an error when it was a stumble, a regional construction, or a transcription mistake. A human listener catches that distinction instinctively. An AI needs to be specifically designed to handle those cases. Many tools are not.
None of that means automated spoken English assessment is not worth using. It means the quality of the system behind the test matters at least as much as the technology itself.
Why CEFR Scoring Makes AI Results Usable
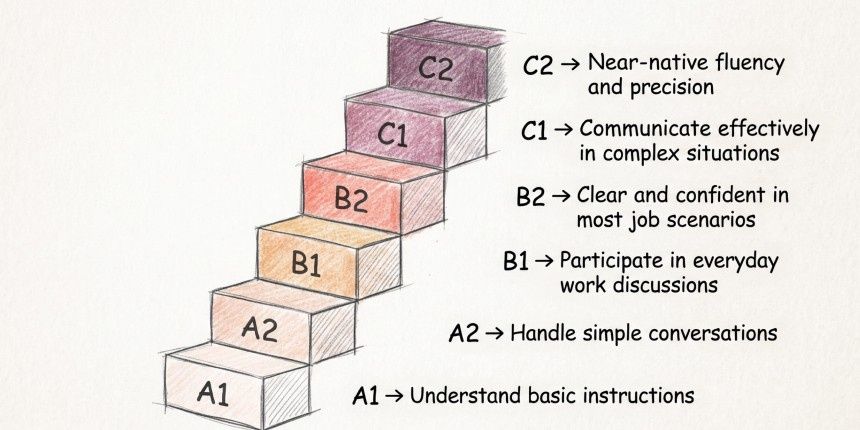
A score of 74 out of 100 does not tell a recruiter much. A CEFR level does. B1 means someone can handle routine workplace conversations but will make mistakes. C1 means they can hold their own in complex professional discussions on topics they have not prepared for. That distinction is immediately useful when you are deciding who gets in front of a client.
The CEFR framework, published by the Council of Europe, runs from A1 through C2 and is recognized by schools, employers, and governments across the world. A CEFR level means the same thing in Singapore as it does in Germany or Canada, which makes it genuinely useful for global hiring.
There is also an accountability angle. 'This candidate scored C1 on a validated assessment' can be reviewed, challenged, and documented. 'They seemed fluent in the screening call' cannot.
How Hyring's English Proficiency Test Fits Into Hiring
Hyring's English Proficiency Test scores candidates across five areas: fluency, vocabulary, mother tongue influence, grammar, and pronunciation, each mapped to CEFR levels from A1 to C2. The mother tongue influence dimension is worth paying attention to. It goes deeper than the accent. It captures how a candidate's first language shapes the way they build sentences, select vocabulary, and pace their speech, patterns that show up in real professional conversations more than a pronunciation score alone would suggest.
Because the test runs inside Hyring's automated screening workflow, candidates get assessed before a recruiter spends any time reviewing them. For global hiring teams working at volume, that is a meaningful shift. Human evaluation of spoken English gets inconsistent quickly. Fatigue sets in, accent familiarity skews perception, and the standard applied in hour one is rarely the same by hour six. A structured AI English proficiency test cuts through that and gives each candidate the same conditions.
Think of it as a first-stage filter. A strong score is a signal worth acting on. It is not a substitute for an actual conversation.
Key Takeaways
- AI can score spoken English as reliably as human raters on structured tasks, but struggles with spontaneous, extended responses.
- Accent diversity and audio quality are the two biggest variables affecting accuracy in real hiring conditions.
- CEFR-mapped results are what make AI scores actionable. A raw number means little; a proficiency level does.
- AI proficiency testing works best as a screening filter, not a final decision.
FAQs
1. Can an AI English proficiency test replace a human interview?
No, and it is not meant to. It removes inconsistency from early screening and makes it easier to surface strong candidates faster. The real conversation still needs a human on the other end.
2. How accurate is AI at scoring spoken English compared to human raters?
ETS research on SpeechRater puts AI-to-human score correlations at 0.7 to 0.8, roughly in line with how consistently two human raters agree on the same response. AI handles fluency, pronunciation, and grammar well. Longer, more complex responses are harder for it to score reliably.
3. How does AI handle non-native English speakers fairly?
That depends on how the system was trained. Models built on a diverse range of accents perform better across different speaker backgrounds. Tools that score how clearly someone communicates, rather than how closely they sound like a native speaker, tend to produce fairer results for global hiring.
4. What is CEFR, and why does it matter for an AI language test?
CEFR is the Common European Framework of Reference for Languages, published by the Council of Europe. It defines six levels from A1 to C2 and is recognized by educators, employers, and governments worldwide. When AI scores map to CEFR, the results are immediately understandable, no matter the role or region.
5. Is an automated spoken English assessment suitable for all hiring contexts?
It works best for roles where spoken English directly affects performance: customer-facing positions, international teams, and cross-functional roles. For jobs where written communication takes priority, the assessment design should reflect that.




